|
|
|
|
|
qb 北京大学高歌教授展望基础模型在生物信息学领域的应用与影响 |
|
|
论文标题:
期刊:
作者:ziyu chen, lin wei, ge gao
发表时间:24 july 2024
doi:
微信链接:
基于transformer架构的基础模型(foundation models)于近年来引领了深度学习领域从小尺度有监督训练向大尺度自监督预训练的范式转变,以chatgpt为代表的大语言模型已经深刻地影响了我们的认知与生活,而同样基础模型在生物学领域的研究也初见端倪。
近日,北京大学高歌教授课题组于quantitative biology期刊上发表了一篇题为“foundation models for bioinformatics”的前瞻性综述。文章从基于文本的大语言模型在生物学信息任务上的应用与基于生物学数据预训练的基础模型两个角度探讨了基础模型对生物信息领域的影响,目前的发展与局限性,及潜在的发展方向。

全文概要
transformer架构的出现深刻地影响了深度学习领域,受益于其高并行、易规模化的特性,大尺度的预训练日趋成熟且展现出了良好的下游应用性能与前景。这一基础模型的研究范式也日益深刻地影响着生物信息学领域(图1)。
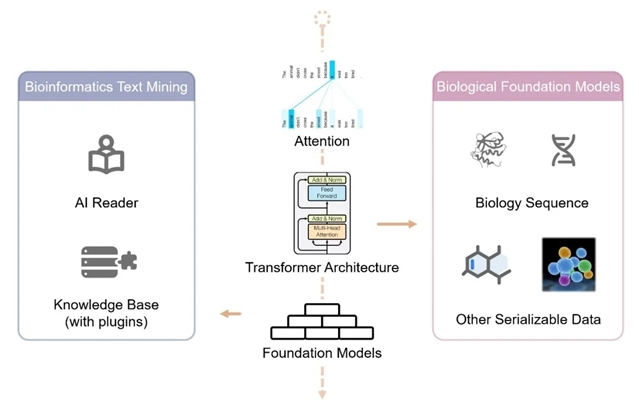
图1. 基础模型在生物信息学领域的应用与影响
基于文本的大语言模型在生物信息学领域的应用主要得益于其两方面的能力:1. 作为“ai 读者”,大语言模型具有良好的上下文关系提取和总结的能力,适用于大规模的文献信息检索与抽提;2. 作为“含插件的知识库”,大语言模型可以回答诸如基因互作、细胞类型注释等生物学问题,但受限于“幻觉”现象的影响,此类应用一方面仍需探究并明确大语言模型的能力边界,另一方面也可以通过提示词工程、检索增强生成(rag)等方式提升其在生物学问答上的表现。
基于生物学数据的基础模型则在生物序列数据(dna、rna和蛋白质)和非序列化数据(小分子和单细胞组学数据)中均有应用。针对生物序列数据的基础模型,文章探讨了其设计过程中的一系列核心选择,以及蛋白结构预测、蛋白质工程等下游应用。针对非序列化生物学数据,核心则在于如何合理地将其进行序列化以适于transformer模型架构并应用于下游任务,相较于小分子领域成熟的smiles表示,单细胞组学数据的序列化则更为复杂,目前主要包括基于表达量的排序和基于替换位置编码的两大类方法。经过序列化预训练的基础模型可被应用于小分子性质和互作预测、细胞类型标注、细胞扰动预测等下游任务。
最后,文章还总结并探讨了生物信息领域基础模型的潜在发展方向,包括transformer自身的可解释性、基于生物学数据基础模型的尺度率、大规模清洗数据集的重要性、跨文本与生物数据或跨多组学的多模态模型等。
qb期刊介绍
quantitative biology (qb)期刊是由清华大学、北京大学、高教出版社联合创办的全英文学术期刊。qb主要刊登生物信息学、计算生物学、系统生物学、理论生物学和合成生物学的最新研究成果和前沿进展,并为生命科学与计算机、数学、物理等交叉研究领域打造一个学术水平高、可读性强、具有全球影响力的交叉学科期刊品牌。
《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、生命科学、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中12种被sci收录,其他也被a&hci、ei、medline或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网

特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负米乐app官网下载的版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。