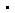|
|
|
中国科学院广州地球化学研究所 |
|
提出基于机器学习的珊瑚微量元素古海水温度计 |
|
|
近日,中国科学院广州地球化学研究所研究人员提出了一种基于机器学习算法改进的珊瑚微量元素古海水温度计,首次系统地评估了机器学习在基于珊瑚微量元素/ca比值的表层海水温度重建中的应用潜力。相关成果发表于《古海洋学和古气候学》。
表层海水温度是研究海洋-大气相互作用和气候变化机制的关键参数。然而,现有的表层海水温度器测记录起步较晚、且覆盖范围有限,难以全面反映长期气候变化。因此,利用珊瑚等气候载体的地球化学代用指标来重建过去的表层海水温度成为理解海洋气候变化的重要方法。
然而,基于δ18o、sr/ca、mg/ca、u/ca等指标的古海水温度计受到非环境因素和“生命效应”的干扰,影响了表层海水温度的准确重建。尽管研究者提出了改良的li/mg、sr-u温度计以及多元素表层海水温度校准方案来应对这些问题,但效果并不理想,后续研究发现这些改良方法仍然受到珊瑚种属差异的影响。
针对上述问题,中国科学院广州地球化学研究所博士研究生韦雨轩在研究员邓文峰、副研究员陈雪霏、研究员韦刚健的指导下,提出了一种基于机器学习算法改进的珊瑚微量元素古海水温度计。他们分析了来自19个珊瑚的1202个数据集,代用指标包括sr/ca、mg/ca、li/mg、u/ca和b/ca比值,并根据区域和珊瑚种群限制将数据分为四个子数据集,使用不同的代用指标组合和机器学习策略训练了1612个模型,以评估非表层海水温度效应对机器学习模型普适性的影响。
该研究发现:非表层海水温度效应主要归因于区域差异而非珊瑚种群差异,突显了区域因素在基于porites珊瑚代用指标重建表层海水温度中的重要性;非线性方法的均方根误差(rmse)小于0.90℃,在引入特定的区域和珊瑚种群限制后进一步降低至0.72℃。
此外,sr/ca和li/mg被认为是表层海水温度的最优指标,显示出与温度更为明确的关系,在仅针对这两个代用指标的独立测试集中,树模型算法表现尤为优异,相较于多元素表层海水温度校准方案和li/mg温度计方程,平均rmse至少降低了0.52℃。
该研究将机器学习方法应用于珊瑚地球化学的古海洋和古气候研究,首次系统地评估了机器学习在基于珊瑚微量元素/ca比值的表层海水温度重建中的应用潜力,特别突出了树模型算法的有效性,以及sr/ca和li/mg在表层海水温度重建中的优越表现
上述研究得到国家重点研发计划项目、中国科学院战略性先导科技专项、国家自然科学基金项目、中国科学院青年创新促进会及中国科学院广州地球化学研究所“涂光炽优秀青年学者”计划项目的联合资助。
相关论文信息:https://doi.org/10.1029/2024pa004885
 机器学习模型的训练流程。
机器学习模型的训练流程。
?
 不同模型性能随代用指标组合数量增加的变化。
不同模型性能随代用指标组合数量增加的变化。
?
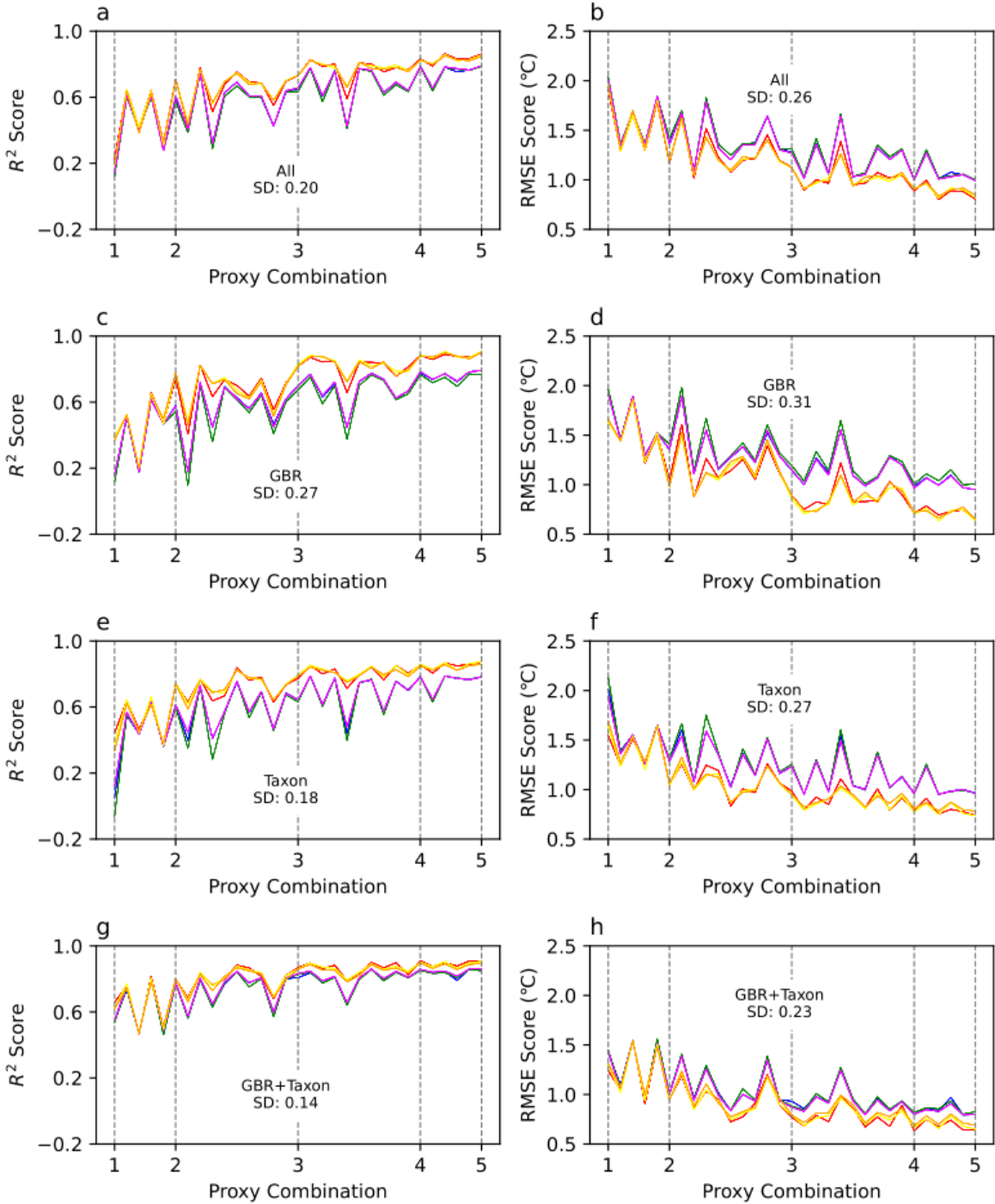
 未限制珊瑚种群和区域的数据集模型性能以及对应的代用指标组合。
未限制珊瑚种群和区域的数据集模型性能以及对应的代用指标组合。
?
 支持向量机回归a、极限随机树回归b、随机森林回归c对不同指标的重视程度。本文由研究团队供图
支持向量机回归a、极限随机树回归b、随机森林回归c对不同指标的重视程度。本文由研究团队供图
米乐app官网下载的版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。